In the spring of 2024, the Data & AI user research team conducted a jobs-to-be-done (JTBD) research study to impact the roadmap for watsonx.data. Using Anthony W. Ulwick’s JTBD framework, I partnered with another researcher to investigate what data engineers needed to "ingest" data.
Due to the nature of this project, I have omitted detailed information and am focusing on the process.
Researcher
Research, Surveying, Usability Testing
October 2023 - December 2023
Desk Research
Conducting desk research involved reviewing the JTBD study of a previous Data & AI research team, reading about data stores, and learning about the JBTD process.
Internal SME Interviews
We conducted 17 interviews with internal Subject Matter Experts (SMEs) for the IBM products set to integrate with watsonx.data. We met with PM, Design, Engineering, and Sales over the course of 2 weeks with the following objectives:
Outline the (preliminary) main job
Validate the job executor is a data engineer.
Synthesis
Based on the internal interviews, we created a hypothesized main job for data engineers doing data ingestion

Hypothesized Main Job
Key Findings
Ingestion is often understood as “Extract and Load,” with “Transform” being optional.
The Data Engineer’s challenges during data ingestion have to do with data governance and intended use
Maturity and size of company define the roles and their boundaries of responsibilities
Screener
Other research squads were conducting JTBD studies for data engineers involved in data preparation and governance. It was at this point that the squads converged to create screeners. Because data engineers have responsibilities that can overlap across ingestion, preparation, and governance, we wanted to allow participants to participate in a maximum of two interviews across squads.
External Interviews
The Ingestion squad conducted 9 interviews with people who identified skills that reflected our hypothesized main job of building solutions to move data from a source to a target storage system in preparation for business-relevant tasks. We met with data engineers in addition to system engineers, data scientists, senior data analysts, and a head of technical architecture and IT operations.
Synthesis
Synthesis of the interviews followed the steps outlined by Anthony W. Ulwick. We outlined the job steps, social aspects, emotional aspects, needs, and the circumstance of data engineers focused on data ingestion.
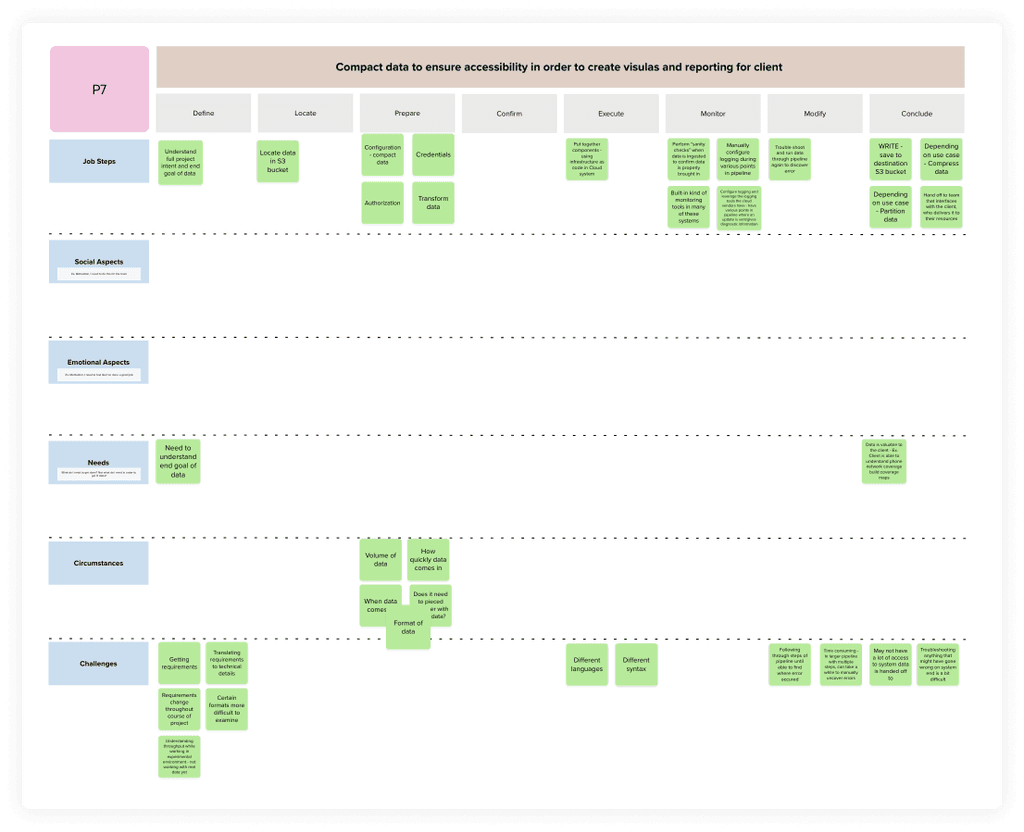
Synthesis template used to outline the job steps, social aspects, emotional aspects, needs, and circumstances of data engineers focused on data ingestion.
Revised Main Job
The hypothesized man job was revised to reflect data discovered in the interviews. The revised main job of data engineers ingesting data is to move data to a centralized repository for use by downstream stakeholders.
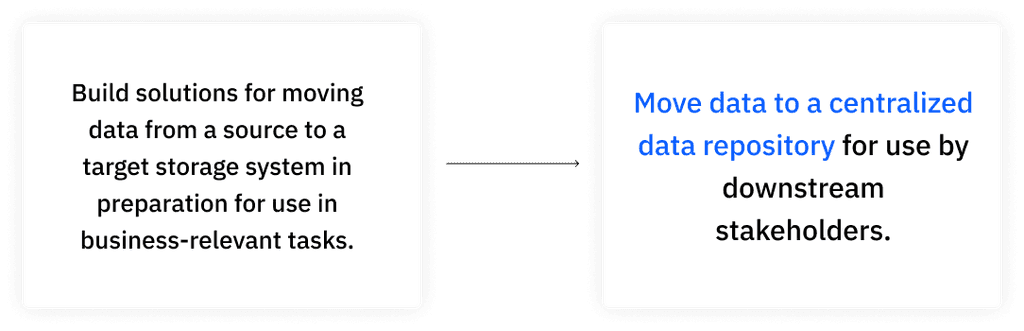
The hypothesized main job was revised based on our findings.
Job Map
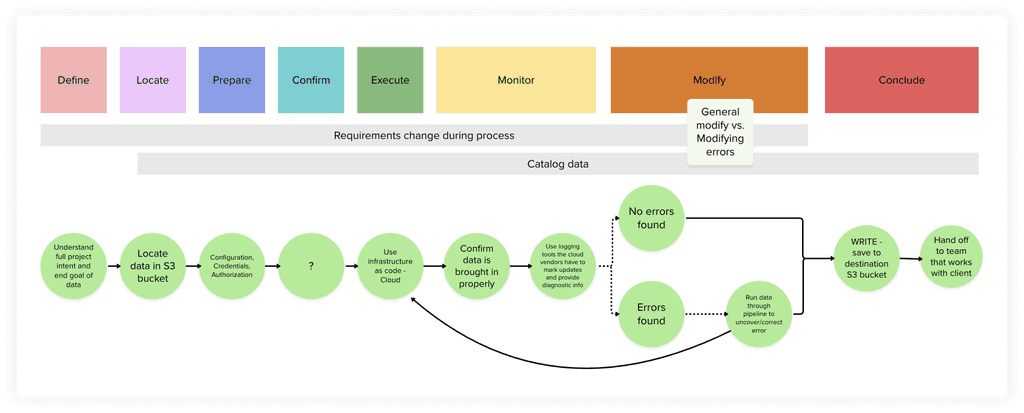
The next step was to create a job map that reflected the revised job statements and placed the job steps into one of eight phases: define, locate, prepare, confirm, execute, monitor, modify, conclude.
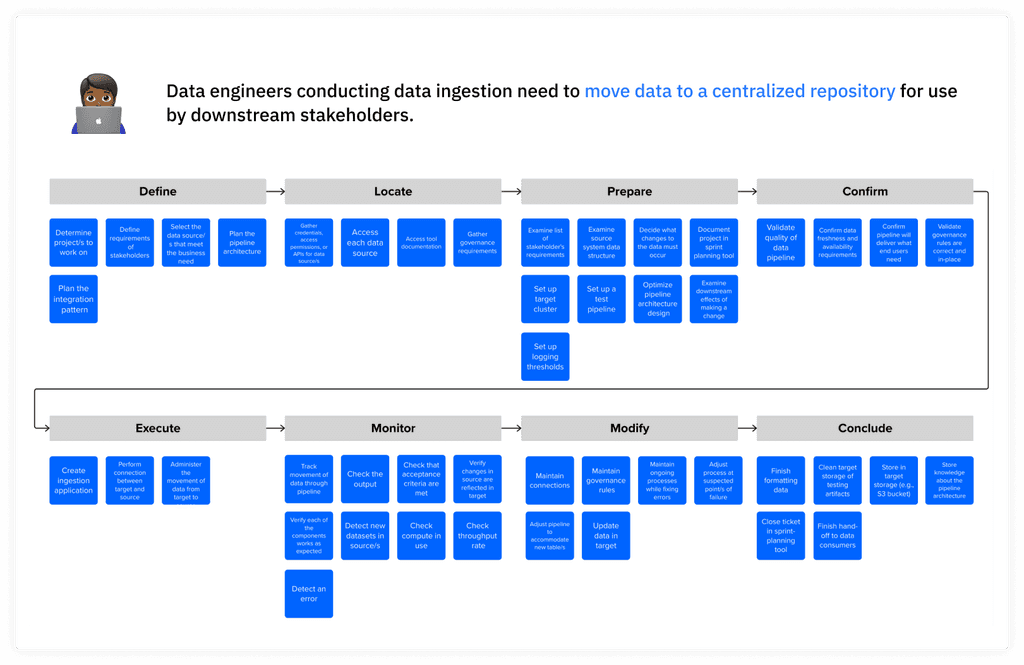
Job map for data engineers doing data ingestion that placed their job steps into one of eight phases: define, locate, prepare, confirm, execute, monitor, modify, and conclude.

48 utcome statements for data engineers before, during, and after data ingestion.

We identified what we believe to be the most impactful outcomes for each phase.
This was my first time teaming up with other user researchers for a project. Working with others who had similar skills was rewording because I was able to learn how others conducted research.
My previous studies involved more testing and was at times more straightforward. Due to the nature of this study, I found myself confused or frustrated because at times. During this process, I sharpened my question-asking skills and became more comfortable in ambiguity.